IA não gera código legado. Quem gera é você.
O problema nunca foi o modelo. Foi a falta de critério antes do prompt.


Tem uma frase que eu ouço bastante de desenvolvedor mais cético: “IA gera código legado”. E eu entendo o sentimento. Quem nunca pediu uma feature pro Claude, recebeu duzentas linhas de TypeScript que rodam de primeira, e três semanas depois descobriu que o coitado do código tem três camadas de abstração que ninguém pediu, um padrão de erro inconsistente com o resto do projeto e um teste unitário que mocka exatamente a coisa que precisava ser testada?
A questão é que esse código não foi gerado pela IA. Ele foi pedido por você.
Eu venho usando agente de IA pra codar de forma séria há um bom tempo e, depois de quebrar a cara algumas vezes, cheguei numa conclusão que parece óbvia mas é desconfortável: a IA é uma máquina de amplificar critério. Se você tem critério, ela acelera a entrega de coisa boa. Se você não tem, ela acelera a entrega de coisa ruim. A velocidade é a mesma. O que muda é o que sai do outro lado.
O ponto é que existe um trabalho que precisa estar feito antes de você abrir o agente. Quando ele não está feito, o modelo escolhe sozinho. E o que ele escolhe sozinho quase sempre é o caminho mais genérico possível.
Personas antes de qualquer linha
Toda vez que eu pulo essa etapa, eu pago depois. Sem exceção.
Quando você pede pra IA construir uma feature sem dizer pra quem ela é, o modelo vai resolver o problema técnico genérico. Vai assumir que o usuário é mediano, que vai usar o produto da forma mais óbvia, que entende um pouco de tecnologia mas não muito. O resultado é um Frankenstein de UX que serve pra ninguém em específico.
Eu mantenho um arquivo de personas no projeto. Não é um documento de marketing com nome inventado e foto de banco de imagem. É um inventário curto: quem usa, qual o nível técnico, qual o contexto de uso (mobile no metrô? desktop no escritório? voz no carro?), qual a tolerância a erro, qual a frequência de uso. Quando eu peço uma feature, esse arquivo entra no contexto e o modelo passa a decidir nuances de implementação a partir disso.
Um exemplo bobo: validação de formulário. Pra uma persona que usa o sistema dez vezes por dia, validar campo por campo é fricção desnecessária, ela já sabe os erros que comete. Pra uma persona que vai usar o produto uma vez, validar tudo no submit é cruel. Sem persona definida, o modelo escolhe um padrão genérico. Com persona definida, ele escolhe o padrão certo.
Use case diagrams e por que UML voltou a importar
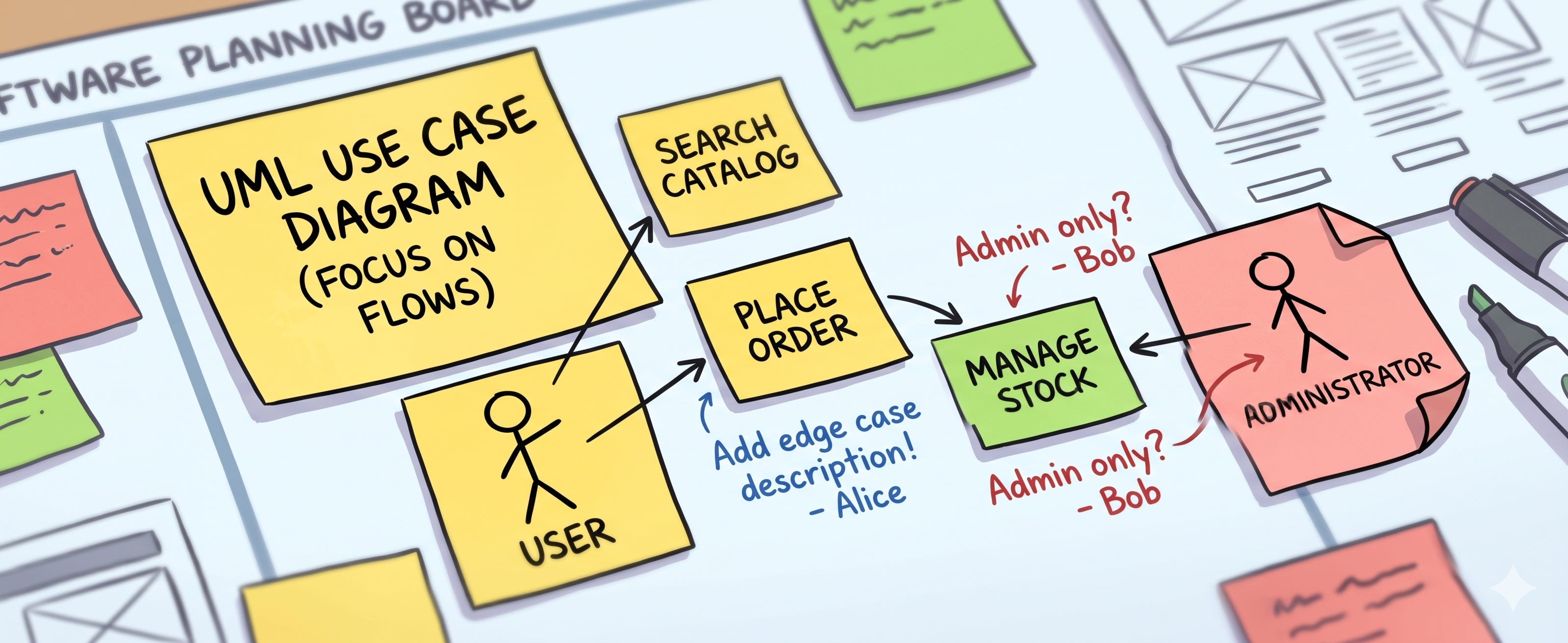
UML virou meio palavrão na última década. Mas a IA mudou o cálculo. Ela lê diagrama de caso de uso melhor do que lê descrição em linguagem natural.
Quando eu passo um caso de uso pro modelo na forma de uma lista de bullets ou um texto descritivo, ele tem que adivinhar as fronteiras: o que é ator, o que é caso, o que é extensão, o que é inclusão. Quando eu passo o mesmo conteúdo em PlantUML, com actor, usecase, extends, includes, ele para de adivinhar. A estrutura formal funciona como um esqueleto que o modelo preenche com músculo.
Não precisa ser bonito. Eu escrevo PlantUML em arquivo .puml direto no repositório, na pasta docs/, e referencio quando estou pedindo uma feature que mexe com fluxo de usuário. O modelo entende, e mais importante, eu posso voltar nele daqui a seis meses e entender o que eu queria.
Banco de dados é onde o legado realmente nasce
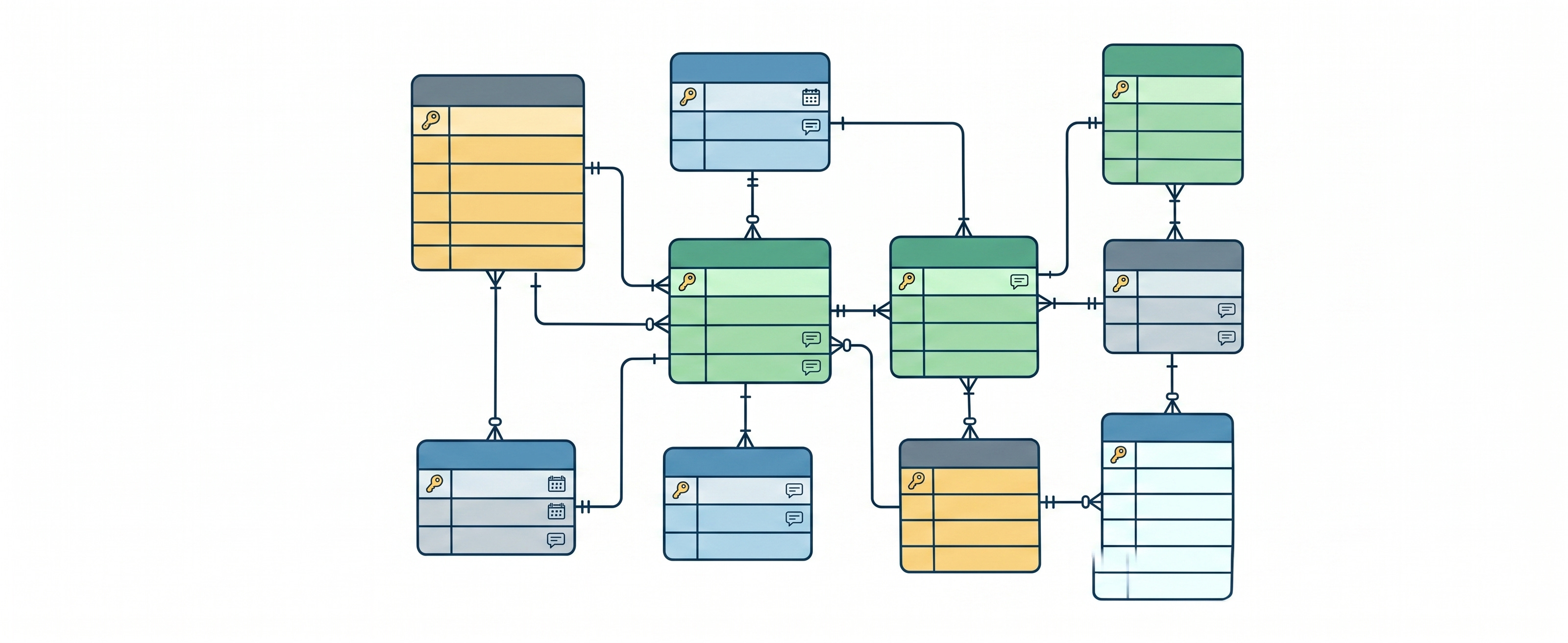
Código ruim você refatora numa tarde. Banco de dados mal modelado vai te assombrar por anos.
Esse é o lugar onde eu sou mais rigoroso com a IA. Antes de pedir qualquer migration, eu tenho um diagrama do banco. Pode ser dbdiagram.io, pode ser Mermaid, pode ser um SQL puro com comentários. O importante é que o modelo enxergue o estado atual antes de propor o estado futuro.
Sem isso, o agente vai gerar uma tabela users com email, password, created_at e seguir feliz. O que ele não sabe é que você já tem uma tabela accounts que faz exatamente isso, que o login do seu sistema é por OAuth e você nem armazena senha, que o created_at no resto do projeto se chama inserted_at por convenção do framework. Cada uma dessas decisões pequenas, repetida ao longo de meses, vira aquele tipo de dívida que ninguém quer pagar.
Eu trato o schema como o ativo mais valioso do projeto. Antes de qualquer prompt que envolva persistência, o diagrama atualizado vai no contexto. Sempre.
Arquivos de contexto: o que vai e o que fica de fora

Aqui é onde a maioria das pessoas erra, eu inclusive.
A tentação é jogar tudo no contexto. O codebase inteiro, toda a documentação, os tickets do Jira, os comentários do Slack. Mais contexto é melhor, certo?
Errado. Mais contexto relevante é melhor. Mais contexto qualquer é caro e atrapalha.
O que eu faço é manter arquivos de contexto temáticos e curtos. Um CONTEXT_API.md que descreve a convenção de endpoints, padrões de erro, autenticação, paginação. Um CONTEXT_FRONTEND.md com a stack, padrões de componentes, biblioteca de UI, regras de acessibilidade. Um CONTEXT_DOMAIN.md com o vocabulário do negócio, porque a IA precisa saber que “rota” no meu produto significa uma coisa muito específica e não a coisa que o Express chama de rota.
Quando vou pedir uma feature, eu seleciono quais desses arquivos vão entrar. Feature de frontend não precisa do contexto de banco. Feature de relatório não precisa do contexto de autenticação. Cada arquivo tem entre 100 e 300 linhas, é fácil de manter atualizado, e o agente recebe só o que precisa.
Isso economiza tokens, sim, mas o ganho real é outro: o modelo fica mais focado. Quando você manda quarenta arquivos pra ele, ele vai puxar referência de qualquer canto. Quando você manda quatro, ele puxa do lugar certo.
ADRs: a memória que o agente não tem
Esse aqui demorei pra absorver. Hoje é uma das coisas que mais me poupa retrabalho.
ADR é Architecture Decision Record. Um arquivo curto, geralmente Markdown, que descreve uma decisão técnica que foi tomada no projeto, o contexto em que foi tomada, as alternativas consideradas e o que pesou na escolha. Não é documentação no sentido tradicional. É um registro do “por que” das coisas.
A primeira vez que eu vi valor real foi quando o agente, três meses depois de uma decisão, sugeriu refatorar algo que tinha sido decidido com motivo. A sugestão era boa em tese, mas ignorava uma restrição de integração com um sistema externo que a gente já tinha brigado pra acomodar. Sem ADR, eu teria que reabrir a discussão, lembrar dos detalhes, talvez aceitar a refatoração e descobrir o problema de novo. Com ADR, o modelo lê, entende a restrição, e propõe uma alternativa que respeita a decisão.
O formato que eu uso é simples. Numera os arquivos sequencialmente, 0001-uso-de-jwt-vs-sessao.md, 0002-banco-postgres-vs-mongo.md. Cada um tem cinco seções curtas: contexto, decisão, alternativas, consequências, status. Status importa porque decisão antiga pode ser revogada, e você quer que o agente saiba quando uma escolha foi superada.
O ganho vai além da IA. Time novo entra no projeto e lê os ADRs em uma hora. Cofundador volta de férias e entende o que mudou. Você mesmo, daqui a um ano, lembra do raciocínio sem precisar reconstruir tudo do zero. A IA só é mais um leitor desse mesmo material, e o melhor é que ela respeita.
Testes unitários como instrumento de design, não de cobertura
Eu confesso que durante muito tempo achei que pedir teste unitário pra IA era perda de tempo. Ela escrevia teste que testava a implementação, não o comportamento. Mockava o que não devia. Cobria casos felizes e ignorava as bordas.
O que mudou foi a ordem. Eu passei a pedir o teste antes do código.
Não é TDD no sentido clássico. É mais um TDD conversacional. Eu descrevo o comportamento esperado em linguagem natural, peço pro agente escrever os testes primeiro, reviso esses testes com cuidado e só depois libero a implementação. Quando o teste está bom, o código que sai pra fazer ele passar é quase sempre bom também.
Esse passo de revisar o teste é onde mora o critério. Eu olho cada caso e pergunto: esse teste reflete uma regra de negócio real, ou é uma armadilha de implementação? Esse mock está simulando uma dependência ou está escondendo um bug? Esse asserção verifica o que o usuário se importa, ou verifica detalhe interno?
Quando você faz isso, o teste para de ser um custo e vira um documento executável do que o sistema faz. E o agente da próxima feature lê esses testes e respeita as decisões já tomadas. É assim que o projeto para de virar uma colcha de retalhos.
Quando o critério não foi aplicado, alguém paga
Recentemente peguei um projeto pra retomar. Código entregue por uma consultoria séria, rodando em produção, com usuários ativos.
A primeira semana de leitura revelou um problema que não era um bug, era estrutural. Uma das entidades centrais do negócio tinha sido modelada no nível errado. Estava presa ao usuário, quando na verdade pertencia à organização. Funcionava, porque na operação inicial era um usuário por organização e ninguém tinha encarado o caso de mais de um.
Acontece que o roadmap do produto pedia evolução pra um modelo onde cada organização teria vários usuários, papéis diferentes, permissões por papel. E essa evolução, com a modelagem do jeito que estava, era cirurgia de coração aberto. Não é uma migration de uma tarde. É reescrever fluxo, reprocessar dado, mexer em integrações já contratadas, e fazer tudo isso sem derrubar quem já está usando.
A consultoria não fez nada que um bom desenvolvedor não faria. Entregou o que foi pedido, o código está organizado, os testes existem. O que faltou foi o passo anterior. Faltou alguém perguntar quem é o ator central de cada fluxo, faltou diagrama de caso de uso que tornasse óbvio onde aquela responsabilidade deveria viver, faltou ADR justificando a decisão. Faltou, basicamente, o trabalho que eu venho descrevendo o post inteiro.
E aqui mora a parte que poucos founders querem ouvir. Quem contrata desenvolvimento de software, seja consultoria, seja time interno, seja freelancer, tem que ter visão de processo. Tem que exigir os artefatos como parte do entregável, no mesmo nível do código. Persona documentada, casos de uso desenhados, diagrama de banco atualizado, ADR das decisões que afetam o produto a longo prazo. Sem isso, o que você compra é um repositório que roda hoje. Não é um produto que dura cinco anos.
Essa documentação não é zelo de arquiteto, é seguro contra dívida cara. A diferença entre pagar pra fazer certo no início e pagar pra desfazer depois costuma ser de uma ordem de magnitude. Às vezes mais.
Vamos pagar essa dívida no projeto que recebemos. Não tem jeito. Mas estamos pagando documentando primeiro, mapeando atores, redesenhando o modelo, registrando o porquê das mudanças. Pra que da próxima vez, quando o produto for evoluir de novo, ninguém precise descobrir do zero o que cada coisa significa.
Onde a responsabilidade foi parar
Tem uma percepção comum de que usar IA pra codar é “ficar parado vendo o modelo trabalhar”. Não é a minha experiência.
O que aconteceu foi um deslocamento. O tempo que eu gastava digitando código agora eu gasto preparando contexto, revisando teste, refinando diagrama, decidindo arquitetura, recusando sugestão. O volume de digitação caiu, o volume de decisão subiu.
E com a decisão vem a responsabilidade. Documentação, persona, caso de uso, ADR. Antes eram coisas que o gestor cobrava do desenvolvedor, e o desenvolvedor entregava se sobrasse tempo. Agora são coisas que o desenvolvedor precisa fazer pra si mesmo, porque sem elas o agente entrega o caminho mais genérico possível.
Quem espera o gestor pedir já perdeu. Quando o gestor pede, o código ruim já foi pra produção, a entidade já foi modelada no nível errado, a decisão já foi tomada sem registro. A janela onde esse trabalho importa é antes do prompt, e quem está no teclado é o desenvolvedor.
Isso muda o que significa ser desenvolvedor sênior. Não é mais o cara que escreve código difícil mais rápido. É o cara que sabe parar de codar pra desenhar, mapear, documentar, registrar. Que entende que esses artefatos não são burocracia imposta de cima, são o material que separa um produto que dura de um produto descartável.
A IA não gera código legado. Ela acelera a velocidade com que você acumula código legado se você não tem nada além do prompt. O remédio não é parar de usar IA. É reconhecer que as coisas chatas que a gente terceirizava pro gestor exigir agora são parte do que significa ser desenvolvedor.
É menos sexy do que a promessa de “deixa o agente codar pra você”. Mas é o que separa um projeto que ainda vai estar de pé em dois anos de um projeto que vai ser jogado fora junto com a próxima virada de stack.